
EulerGUI Manual
© Jean-Marc Vanel - $Date: 2012-11-08$ - under Creative Commons License by-nc-nd 3.0
In sync with EulerGUI release 1.12 - Latest User Manual from Subversion.
TOC
The EulerGUI Integrated Development Environment (IDE) allows one to develop and run rules in N3 logic language, applied to data and models in various formats converted in N3 syntax (Notation 3). The sources can be N3, RDF, or OWL, SPARQL queries, UML, eCore, plain XML, XML Schema, files or URL's. Internally everything is expressed in N3 syntax, being a convergence language that allows to express data (facts), classes and properties, and rules. N3 is the main language for the Semantic Web, being much more readable and concise than RDF (Resource Description Format). Compared to pure point-and-click tools like Protégé, EulerGUI is centered on textual editors for N3 source.
To design rules, one must have data, so EulerGUI has facilities to Explore Semantic Web .
EulerGUI is convenient for developing and testing projects composed of various ontologies and data sources, with rules in N3 logic. One can launch 4 reasoning engines: Euler proof engine , CWM , Drools, and FuXi .
For each source it can show a Graphviz graph. From the inference result, one can trigger Java objects creation, or generate Javascript+Java code.
EulerGUI is more than a Development Environment, it is a framework to build rule-based applications on several platforms; see paragraph "EulerGUI application building Framework" .
The EulerGUI project is strongly connected to the Déductions project.The Déductions project aims at using Artificial Intelligence techniques for general software development tasks. Currently it has rules in N3 language to generate simple Create-Update applications for Java Swing platform from OWL models. Déductions also includes rules for converting UML, eCore, RDFS to OWL, SWRL into N3. The rules in Déductions are of course developed using EulerGUI.
EulerGUI also aims to become a lightweight IDE for Artificial Intelligence; N3 is able to represent full First Order Logic, and we plan to add more formats in input and output: TPTP, KIF, CLIPS, pure Prolog, and more reasonning engines like Prover9 .
This documentation is made with open source XHTML editor Amaya from INRIA. To facilitate revision mangement and ensure XHTML code quality, contributors are invited to use this nice tool.
System Requirements
GUI
syntax coloring, tooltip with explanations about the resource under the mouse;
HTTP connection to prefix.cc site for filling missing N3 prefixes;
when an N3 file is modified on disk or Internet, it is re-parsed, and syntax errors are highlighted
in editor, pull-down menu to open Web page or add URI to project
$HOME/.eulergui_preferences.n3Inputs
Rule engines
kb:retract;
this is developed within the EulerGUI project
Viewers and exports
Tools
API (framework )
You must have installed a Java(TM) 2 Runtime Environment (JRE), Standard Edition version 1.6 or later, from http://java.sun.com . Of course the Java(TM) 2 Development Kit (JDK) includes a JRE.
On Linux, you can install most of the required packages in a single command .
EulerGUI is developed on Ubuntu Linux, and tested regularly on Windows, and should run everywhere a Java Runtime Environment exists.
On MacOSX 10.5, you have to activate Java 6 manually. Procedure: click on " /Applications / Utilities / Java / Java Preferences" ; various versions of Java are available and the one by default is Java 5 instead of Java 6. It is necessary to put Java 6 first in the list.
On MacOSX 10.6, Java 6 is there already.
However, the Yap Prolog engine is not provided in the EulerGUI jar. In order to use the Euler engine, you have to install Yap yourself. And unfortunately, no binary is provided by the Yap team (as of december 20110). So you have to install Yap from sources, as explained in the Euler site.
The only scripting engine for java installed by default under OSX is AppleScript. If you want use the Java generation feature , it is necessary to install the engine for JavaScript; the procedure is the following :
tar xvzf), open the folderin /Library/Java/Extensions/ .
Many thanks to Vincent Aravantinos for solving the problems under Mac.
Download from Sourceforge - Euler GUI
The release is a single executable jar, so to launch it, just click on it a file manager, or type this from a shell:
java -jar eulergui-1.9-jar-with-dependencies.jar
Then you can open e.g. this project: http://deductions.svn.sourceforge.net/viewvc/deductions/n3_nojs/person_import3.n3p by drag'n'drop or by clicking File / open project from URL. Throughout this Manual, when you see a .n3p URL, it's an EulerGUI project downloadable from the Internet in a single drop.
Building EulerGUI from sources
If you want to test a snapshot, bleeding edge beta stuff (but with all tests passed) , look here on the Maven repository, and take the latest SNAPSHOT
http://eulergui.sourceforge.net/maven2/eulergui/eulergui/
( to refresh the page and the timestamp of the jar, do shift+reload in your Web browser ).
To know which features are in the snapshot, you can look the CHANGELOG in the software depot, or more accurately the log view
of the latest changes in the Java source.
Download from http://sourceforge.net/projects/eulergui/files/eulergui/1.11/
The Minimal EulerGUI has exactly the same licence as Maximal (full) EulerGUI, that is LGPL. It is just a simpler version for Semantic Web users, who are not interested in other the features of full EulerGUI: importing UML, XMI, XML, and Java framework for application building. Only one inference engine is available: Euler EYE engine ( http://eulersharp.sourceforge.net/ ).
Main features:
Sorry for the large size (37Mb), soon we will remove unnecessary dependencies.
The following third party Java open sources libraries are included in this jar:
Accurate and up-to-date information about third party Java open sources libraries can be found on this dependencies page generated by Maven , including transitive dependencies, dependency tree, repository locations and more.
![]()
![]()
![]()
![]()
![]()
Although Euler GUI runs perfectly without any external tool, they make work
easier. To be launched by Euler GUI, all these tools should be in the user
path. But (for Linux users) using a alias in the shell will not always work,
you need to have cwm and FuXi in your path. Normally
the installation of CWM and FuXi does that: otherwise you can do:
ln -s /path/of/your/cwm $HOME/bin
Visually the correct installation of the facultative external tools can be seen by the activation (grey or colored) of the buttons for CWM, FuXi, and graph visualization .
only when NOT on Linux or Windows :
alias cwm=$HOME/src/swap/2000/10/swap/cwm.py
sudo apt-get install python2.6-dev mercurial wget http://peak.telecommunity.com/dist/ez_setup.py sudo python ez_setup.py sudo easy_install -U "rdflib==2.4.2"
then (on Linux or cygwin) the Mercurial repository can be cloned and installed via:
hg clone https://fuxi.googlecode.com/hg/ fuxi cd fuxi # at any time to download latest code: hg pull hg update python setup.py build sudo python setup.py install
Well this is not enough; today (2011-09) , the correct recipies (for ready-made FuXi or from sources) are here :
External editor, that is system default editor, or gvim
when installed, is now disabled by default. To enable it, the switch is method
ProjectGUI.useExternalEditor() .
To install and configure Vim :
It' not necessary to add Vim in the system path on Windows.
You might want to read this page about installing the programmer's editor Vim on Windows :
https://www.fieldstone-software.net/docs/machine_setup/Articles/gVim.html
http://www.vim.org/scripts/script.php?script_id=944
n3.vim in directory .vim/syntax (on Windows
C:\Program Files\Vim\vimfiles\syntax ).vim/filetype.vim in your home directory
(on Windows C:\Program Files\Vim\vimfiles\filetype.vim )
: augroup filetypedetect
au BufNewFile,BufRead *.n3 setfiletype n3
au BufNewFile,BufRead *.ttl setfiletype n3
au BufNewFile,BufRead *.nt setfiletype n3
au BufNewFile,BufRead *.sparql setfiletype n3
au BufNewFile,BufRead *.turtle setfiletype n3
" when reading HTTP URL's:
au BufEnter *.n3 setfiletype n3
au BufEnter *.ttl setfiletype n3
au BufEnter *.nt setfiletype n3
augroup END
augroup filetypedetect
au BufNewFile,BufRead *.rdf setfiletype xml
au BufNewFile,BufRead *.owl setfiletype xml
augroup END
augroup filetypedetect
au BufNewFile,BufRead *.yap setfiletype prolog
au BufNewFile,BufRead *.bnf4 setfiletype pccts
au BufNewFile,BufRead *.drl setfiletype perl
augroup END
On Linux 64-bits systems, you may have this message when launching EulerGUI:
/tmp/eye/linux/bin/yap: error while loading shared libraries: libncurses.so.5: wrong ELF class: ELFCLASS64
All shared objects copied by Euler from the EulerGUI jar are ELF 32-bit LSB shared object, Intel 80386. The dynamic linker must find all 32-bit libraries required by Euler, and for that you need to install package ia32-libs :
apt-get install ia32-libs
After having Installed and run EulerGUI, there are lots of ready made projects. Just drag'n'drop them in the middle of the frame, where "drag'n'drop" is written. You can also use the menu File / open project from URL.
See also Examples below.
WE WELCOME BUG REPORTS, SUGGESTIONS AND USER REPORTS.
SourceForge Support Request; you can also send a mail directly to the project leader : <jeanmarc.vanel@gmail.com> .
Professional support on EulerGUI, EulerGUI server, OWL modeling, controled Natural Languages and more is available here:
http://deductions-software.com
The mailing list eulergui-user in SourceForge ; subscribe to the mailing list eulergui-user .
The mailing list deductions-user in SourceForge ; subscribe to the mailing list deductions-user (discussions on the rule bases and the application generator in project Déductions).
Let's meet here for IRC chats:
log : swig.xmlhack.com
( use e.g clients Pidgin on Windows, XChat on Linux ) .
There is also a discussion group in French here: Déductions et EulerGUI en Français .
Nearby and besides EulerGUI, there are many interesting communities:
Semantic Overflow, for questions about semantic web techniques and technologies.
IRC chats: #swig, #foaf, ##AGI
On this site:
In french:
EulerGUI and Semantic Web Videos at OSDC 2012 :
In english:
On other sites:
Course In french:
SPARQL Protocol and RDF Query Language : http://fr.wikiversity.org/wiki/SPARQL
Videos :
You have a comprehensive list of ready_made projects in paragraph "Getting started".
it is also possible to drag and drop one or more URL (N3, RDF, OWL, XMI, UML) from a file manager or web browser ( tested with Firefox and Konqueror ), for example the result of a search on Swoogle
for Euler if you add any argument, nothing is automatically added (except the list of URL's), you must provide all arguments, e.g. :
--sem --test-as --step 1000000
ff you need the full power of the command line arguments, see below "Expand engine arguments feature"
click the button bearing the Euler logo (the cube) , or type enter in field for arguments ;
The list of arguments available for Euler using Yap Prolog (EYE) can be obtained by running the engine with argument
--help
The list of arguments currently available are:
Id: euler.yap 5348 2012-05-21 13:57:14Z josd YAP 6.2.3 (i686-linux): Wed Feb 8 11:14:50 CET 2012 starting 80 [msec cputime] 100 [msec walltime] Usage: eye <options>* <data>* <query>* eye java -jar Euler.jar [--swipl] [--no-install] yap -q -f euler.yap -g main -- swipl -q -f euler.yap -g main -- <options> --nope no proof explanation --no-branch no branch engine --no-qvars no quantified variables in output --no-qnames no qnames in output --no-span no span control --no-varpred no variable predicates --quiet incomplete e:falseModel explanation --quick-false do not prove all e:falseModel --quick-possible do not prove all e:possibleModel --quick-answer do not prove all answers --think generate e:consistentGives --ances generate e:ancestorModel --plugin <yap_resource> plugin yap_resource --wcache <uri> <file> to tell that uri is cached as file --ignore-syntax-error do not halt in case of syntax error --pcl output PCL code --strings output log:outputString objects --warn output warning info --debug output debug info --profile output profile info --statistics output statistics info --version show version info --help show help info <data> <n3_resource> n3 facts and rules <query> --query <n3_resource> output filtered with filter rules --pass output deductive closure --pass-all output deductive closure plus rules
See Also about Euler / EYE engine
Expand engine arguments feature
Before launching inference engines Euler / EYE, CWM or Fuxi,, EulerGUI expands arguments entered in the input field:
So * is a placeholder for the list of (activated) N3 sources, and -q for N3 query term. This feature has the following advantages:
Here is an example project for this feature: test/BloodPressure.n3p .
you can even add a query by preceding it with --query (or -q) like in EYE's arguments (see above);
you can even add some Euler / EYE options; this way a complete EYE command line is turned into an EulerGUI project, for example:
eulergui --nope --quiet --quick-possible http://eulersharp.sourceforge.net/2007/07test/alpP001.n3 http://eulersharp.sourceforge.net/2007/07test/alpA010.n3 --query http://eulersharp.sourceforge.net/2007/07test/alpQ001.n3
Moreover, since the EulerGUI jar includes many other libraries, on can use their commands. For instance, run Jena ARQ with the EulerGUI jar like this:
java -cp eulergui-1.11-SNAPSHOT-jar-with-dependencies.jar \ arq.rsparql --file query.rq --service=http://www.lotico.com:3030/lotico/query
System Properties :
If autorun=drools , EulerGUI does not show the normal GUI, and
shows directly the generated application corresponding
to the project in command line. For example this starts the "person" generated
application :
java -jar eulergui-1.9-jar-with-dependencies.jar \
-Dautorun=drools \ http://eulergui.svn.sourceforge.net/viewvc/eulergui/trunk/eulergui/examples/person_import3.n3p
If you don't already know, please read Why use a Rule Engine? in Drools engine documentation.
On top of the above advantages, EulerGUI framework adds the following:
Launching one of the inference engines creates a popup by which it is possible to kill the launch.
click on the toothed wheel ( or type enter in field for arguments )
Arguments from GUI (typically --think) are added before
--query=file..., not pre-pended like for Euler engine. If you need the full
power of the command line arguments, see below "Expand engine
arguments feature"
CWM path customization
All the user has to do is to add this:
:cwm a eg:Inference_engine; rdfs:label "CWM"; eg:absolute_path "/usr/bin/cwm" .
in File / Preference menu, or in file $HOME/.eulergui_preferences.n3 .
Cache for Drools compilations
The inconvenient with Drools is that the compilation is quite slow, and can last a few seconds, even for three rules. So we have two caches:
The timestamp of the N3 source files and projects is used to recompile only if necessary.
$HOME/.eulergui/rule_bases_cacheURICacheExport as Drools
If one wants to reuse the facts and Drools rules independently of EulerGUI, one can export the Drools rules base by clicking on File / "Export as Drools". This saves in current directory:
Then to load and run facts and rules independently from EulerGUI, you can use class
eulergui.inference.drools.impl.DroolsRunExportedProject
There is a rule base for Euler engine for "Case Based Fuzzy Cognitive Maps". This rule base is automatically loaded as a subproject whenever this prefix is added to the project:
@prefix fl: <http://eulersharp.sourceforge.net/2003/03swap/fl-rules#> .
More details here CBFCM_EulerGUI ( in french ).
Fuxi is also using a RETE engine to run N3 rules, so it's really comparable to EulerGUI's Drools engine.
An article by the author of FuXi: mapping-rete-algorithm-to-fol-and-then-to-rdf . There is also an end-to-end tutorial for FuXi that attempts to describe (with lots of code examples) its primary capabilities as well as how it works with the other FuXi-related projects (Triclops, layercake-python, etc.). The link is below:
http://code.google.com/p/fuxi/wiki/Tutorial
It is meant as a 'hello-world' tutorial with links into the more detailed documentation
With EulerGUI you have 5 engines ! In fact most of the N3 engines I know are here, except the newest clone of CWM in Scala (swap-scala) by Dan Conolly, and the recent km-rdf - Henry by Yves Raimond in SWI Prolog .
For general purpose, Drools / N3 engine is the best, but the RETE compilation lasts a few seconds; however afterwards it's very quick, probably quicker than if you would code the reasoning by hand. E.g. an input form is generated in a few milliseconds directly from the OWL model (see Java Swing application generator) ! Then, it leverages on Drools rule engine to keep a stateful Knowledge base, so that one can add new triples in a new N3 source, and the results will be updated. This capability is exploited in the EulerGUI server .
For complex reasoning involving peeping into formulas the Euler Prolog engine (EYE) is indispensable (a.k.a. EulerSharp, Eye ). It also has more built-ins (math, strings, logic, RIF). Also for modify-and-test cycle Euler is generally quicker, because there is no rule compilation step, this a all-in-one reasoning engine. A good account of EYE is here : eye-note.txt .
However, it has limitations compared to the Drools engine: creation of blank nodes step by step, like like when creating a form from a model, generally does not work and ends with a message :
** ERROR ** sem ** maximimum_step_count(500000)
Also Euler does not store a state; it has no truth maintenance capabilities like Drools.
CWM is the historic tool written by the authors of N3 logic themselves.
FuXi is in active development by Chimezie Ogbuji.
Other Java rules engines:
http://www.java2s.com/Product/Java/Development/Rule-Engines.htm
EulerGUI includes the full jEdit 4.3.1, the all-purpose Java editor. JEdit is a powerful editor with tens of plug-ins, and syntax colorings ("modes") and tools for the major programming languages. The specific features for EulerGUI are:
rdfs:label in bold, rdfs:comment, labels or N3
term for rdfs:domain and rdfs:range for Properties, and URI of the
declaration; all the N3 sources (activated or not) are searched for
declarations.
Note that you can add add all refered Ontologies to current project, so that all resources having a definition will provide a tooltip in the editor. An example of a project that has been set up with all the ontologies defining the properties and classes is model-rules-coherence.n3p .
of course we are hoping that the same URI will serve HTML when asked by the browser, which is recommanded practice, but not always followed :(
Some convenient jEdit settings: menu Utility / Global Options , then :
check "highlight word at caret"; this highlights every occurence of the word at caret
check "highlight selection under caret";
check "highlight overview"
in Plugins / Highlight : check "Toggle highlights on"
CAVEAT:
$HOME/.jedit/jars/Highlight.jar
If there is an installed jEdit instance, its configuration takes over the one in EulerGUI.
a right-click on a statement in a rule consequent, and choose "possibly entails ..." will show a tooltip or pop-up showing the rules that are possibly triggered by this statement;
ATTEMPTO Controled English (ACE) is a controlled natural language, i.e. a rich subset of standard English designed to serve as knowledge representation language. ACE appears perfectly natural, but — being a controlled subset of English — is in fact a formal (logic) language. There a bidirectional translation of ACE into and from OWL 2 and a translation into OWL+SWRL.
The ATTEMPTO tools are:
ACE includes an ACE --> OWL+SWRL translator. EulerGUI includes an SWRL--> N3 logic translator. ACE stands for "Attempto Controlled English", and is a syntactically and semantically well defined subset of the english language. Together, this allows to have this workflow:
Here is a complete example : friend-prop.n3p . The rule is similar to what FaceBook does, and comes from this ATTEMPTO Controled English text :
If a user U has-as-friend a person X, and has-as-friend a person Y, and X is not Y,
and X has-as-friend Z, and Y has-as-friend Z, and Z is not U then
Z is-a-proposed-friend-for U.
The inference works fine with all 4 engines in EulerGUI.
Another example showing ACE => OWL => N3 rules translation with the FOAF vocabulary .
Here is an overall data flow diagram including both inputs and inference engines :
ACE -1-> OWL+SWRL -2-> N3(ontology+rules) -3-> Drools
! !
v v
Euler, CWM, FuXi Drools
|
v
N3
The first row represents data formats. The arrow 1 is implemeted by ATTEMPTO. The arrow 2 is done by an N3 rule base applied in EulerGUI. The arrow 3 is implemeted by the Java classes DroolsTripleHandler and N3JavaMappingBuiltin .
Depending on project circonstances and team skills, one can enter the train at any "station". Then either Euler engine can be used for one time (batch) run, or Drools for dynamic (stateful) processing.
Here is another view stressing on reuse of existing domain ontologies, supplemented by domain expertise in ATTEMPTO Controled English (ACE), plus functional specifications :

As these formats are the native formats for EulerGUI, the internal N3 parser is used, the parse tree is kept in memory, and the triples are inserted in internal KB.
The N-Triples format is processed somewhat differently. Assuming it is used for big data, the parse tree is not kept in memory, but the triples are also inserted in internal KB.
The UML integration in EulerGUI uses the EMF eclipse infrastructure.
To read an UML file, push the button with the UML logo, or drop an URL ending with .uml, .xmi, or .ecore, or else push the button with the earth logo.
Much like for RDF, the UML (or eclipse eCore) is translated on the fly into N3. Reading XMI from an URL is also possible. The N3 obtained is an straight RDF view of the UML model, where UML properties have become RDF properties, and UML meta-classes have become RDF classes.
There are also rules to translate UML or eCore expressed in N3 into OWL. To perform the translation, add uml_owl-rules.n3 or ecore_owl-rules.n3 to your EulerGUI project. Then to get all the translated OWL objects with all their properties, add this to the project query:
@prefix umlowl: <http://deductions.sf.net/owl/uml#> .
{
?OWL_THING umlowl:translatedFromUML ?UML_THING .
?OWL_THING ?P ?V .
} => {
?OWL_THING ?P ?V .
} .
Note that alas general OWL Restrictions have no direct UML equivalent. This is of course because OWL is based on Description Logics, where class membership is computed. On the contrary in UML, class membership is asserted on object creation. The translation rules, however, create OWL Qualified Cardinality Restrictions from UML Cardinality declarations.
An example of projects including these rules to generate a CRUD mini-application from an UML or eCore model, and using project pipeline (a.k.a. post-processing project) are here:
As an example of an N3 OWL file converted from eCore here is the UML 2.2 metamodel :
http://deductions.sourceforge.net/models/UML2-OWL_model.n3
It would be possible to read XMI following any eCore metamodel, but the corresponding jar would have to be added; the UML2 jar is already 2.3 Mb.
The necessary jars (included in EulerGUI) are :
Elements and attributes are translated into RDF / N3 predicates. More precisely, the "RDF-ization" is as follows:
There is another implementation of a converter for plain XML files or XML Schema, from the Gloze project, a Jena subproject; see "XML to RDF & back again" by S. Battle. This implementation is 100% Java. For the Gloze converter, there is another button with an XML logo to the right of the ReDeFer logo.
Currently the Gloze implementation is more used and tested than Redefer.
CAVEAT:
You can import XML from a file, an URL or D'n'D.

As you can see above, XML Schema can be imported with Gloze; they are translated into OWL. It detects XML Schemata by their extension .xsd .
Here are examples of N3 projects importing XML files :
On importing XML, Gloze is using a no schema mapping for elements that have no XML Schema information. This is quite satisfactory. Moreover, when XML Schema information is present, Gloze is able to add class information (RDF type). Gloze reads schema locations from the XML instances, when present. Otherwise, schema locations for well-known Schemata are hard-coded into EulerGUI; the current known Schemata are defined here as a Map from namespaces to Schema locations in XMLSchemaCatalog.java . We took inspiration from these nice Wikipedia List_of_XML_schemas , and List_of_XML_markup_languages . The XML formats that are recognized on import and export are: XHTML, SVG, MathML, XForms, XSLT, WSDL, DocBook, XBRL, Maven, Dublin Core in XML, UBL (from Oasis), KML (geography).
On exporting XML with Gloze, an XML Schema is mandatory. But again, for well-known XML Schemata, we recorded the "root" RDF URI predicates, in class XMLSchemaCatalog . Basically the problem is that in a general RDF graph there is no such thing as a root. Fortunately EulerGUI is able to detect in a general RDF graph the "root" resource, by searching the "root" RDF URI predicates. For example, for an RDF graph representing an XHTML document, like simple.html.n3 , this predicate :
<http://www.w3.org/1999/xhtml#html>
will be recognized as the root for the conversion to XML . Note that this
does not have to be the first in the N3 document. In fact all the known "root"
RDF URI predicates are searched in the projects's N3 or RDF sources, until a
"root" predicate is found . Then the system property gloze.base is
set to the "root" RDF resource, as if Gloze in command line were used.
Additional Features:
TODO:
xsd: schema, schemaLocation, targetNamespace, xsd: import,
namespace.This feature is currently deactivated, by lack of tests (can be reactivated in class SourceFilesManagement, method addSourceActions).
This reuses the ReDeFer project; more details on the conversion here: the XML2RDF mapping. To import an XML file, push the XML button to the right of the UML button. The XML file is then converted on the fly into an N3 file. No XML Schema is necessary, but when present, the translation is better. The ORIG. button to the far right gives access to the original XML document (the button may not be visible readily, but you can make the window wider to reveal it).
For XML Schema, an XSLT transform from the ReDeFer project is used, that creates an OWL ontology. The usage is as for plain XML files; the suffix .xsd is is recognized.
The Schema already translated are kept in an hsqldb database.
Contrary to Gloze, Redefer does not export an RDF document as plain XML.
The SPARQL query language is for querying RDF data sources. It is also an HTTP protocol. You can find an up-to-date list of servers here: Currently Alive SPARQL Endpoints .
The body of queries has a syntax similar to N3. In EulerGUI, the result of a SPARQL query is considered as an N3 source, just like other sources (like RDF, UML, XML ... ) . All these data and model sources are translated on the fly into local temporary files that are fed to the inferences engines.
Also note the difference in behavior between queries like SPARQL queries, and rules like N3 or SWRL rules. One activation of a rule is like a query, but the result of the activation is added to the Knowledge Base, and can possibly trigger other rules. On the other hand, a SPARQL query can build a complex RDF graph in the CONSTRUCT part, and have several responses, but the result triples are NOT joined to the the Knowledge Base. In fact a SPARQL query is semanticaly like an N3 search of an EulerGUI project. The difference is that a SPARQL query operates on an external RDF endpoint, whereas an N3 search operates on the whole RDF graph of the current project.

To create a new SPARQL query, push the button with the SPARQL icon ![]() (representing sparkles). The query is in a local file
with a
(representing sparkles). The query is in a local file
with a .rqor .sparql suffix. The URL of
the SPARQL service (endpoint) is chosen through an editable combo box. An empty
string means no SPARQL service; in this case the RDF sources being queried are
in the SPARQL query itself, in FROM clause(s).
Example without an endpoint
Here is an example of such a query:
PREFIX table: <http://www.daml.org/2003/01/periodictable/PeriodicTable#>
CONSTRUCT { ?element table:name ?name. }
FROM <http://www.daml.org/2003/01/periodictable/PeriodicTable.owl>
WHERE { ?element table:name ?name. }
A project including this SPARQL query is : examples/periodicTable.n3p
The result is:
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> . @prefix table: <http://www.daml.org/2003/01/periodictable/PeriodicTable#> . table:Te table:name "tellurium"^^xsd:string . table:Pb table:name "lead"^^xsd:string .
NOTE: such a case with no SPARQL endpoint, and RDF source indicated in the FROM clause, is equivalent to adding the RDF source for Periodic Table to an empty EulerGUI project, with the following N3 query:
{ ?element table:name ?name. } =>
{ ?element table:name ?name. } .
So extracting with SPARQL from an explicit RDF URL like the PeriodicTable.owl example is exactly the same as EulerGUI processing from a plain RDF source, except that in a project all sources are processed together with all the rules, which is more powerful .
Examples with endpoint
EulerGUI projects with query examples from:
To redo a query :
Changing the SPARQL endpoint also re-does the query.
The specification of SPARQL language: rdf-sparql-query . A nice tutorial on SPARQL .
As a typical example, this a way to list the names of all musicians found in dbpedia:
prefix dbpedia-owl: <http://dbpedia.org/ontology/>
prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?NAME
where {
?A a dbpedia-owl:MusicalArtist; rdfs:label ?NAME .
}
There are nice examples of complex queries on the DBPedia site :
http://wiki.dbpedia.org/OnlineAccess#h28-5
These language constructs, and all predefined functions, do not to work outside of FILTER clauses :
!=
, as exemplified in http://www.w3.org/TR/rdf-sparql-query/#func-RDFterm-equal :
# This query finds the people who have multiple foaf:name triples:
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?name1 ?name2
WHERE { ?x foaf:name ?name1 ;
foaf:mbox ?mbox1 .
?y foaf:name ?name2 ;
foaf:mbox ?mbox2 .
FILTER (?mbox1 = ?mbox2 && ?name1 != ?name2)
}
Other interesting operators are bound, regex, str ( see the SPARQL query language
specification ).
PREFIX dc: <http://purl.org/dc/elements/1.1/>
SELECT ?title
WHERE { ?x dc:title ?title
FILTER regex(str(?title), "^SPARQL")
}
You can have a look in the ARQ ChangeLog to see implementation details. I also found this interesting page about negation : http://jena.sourceforge.net/ARQ/negation.html .
SPARQL Query Language reference card
Note that only CONSTRUCT queries can generate N3 data. The result of SELECT queries is a table, and is just shown as a table with the table button. Note also that several SPARQL public endpoints produce an empty result and no warning, or a just a HTTP 500 error, when there is something wrong with CONSTRUCT queries. This was the case with dbpedia (running a Virtuoso server), when the property is not a literal. See also warning about generic queries in next paragraph..
To start with nothing but a SPARQL endpoint and to dive in and learn about the data, the basic mechanism by which we can do this is by writing queries that use variables to find all of the predicates and all of the types that exist in a dataset, and then to pick out interesting predicates and types and use open-ended queries to explore the structure of the data. Dean Allemang has written a blog post on this exact subject, so I gladly reference his writing on using SPARQL to explore an unknown dataset.
find_classes.sparql
SELECT DISTINCT ?Concept WHERE {?x a ?Concept}
find_properties.sparql
SELECT DISTINCT ?p WHERE {?s ?p ?o}
Note that as writen above, these 2 exploring queries may fail on many endpoints, due to limitations in result size or elapsed time . In this case add this at the end:
LIMIT 200
But even this is not enough, and many sites like dbdepia return HTTP 500 error with this. So it's good to know the vocabulary used from the documentation, and not rely on such generic queries.
it works much like basic SPARQL, except that the syntax is now the syntax from the Squall project .
The executable squall2sparql must be in the path.
The default prefix is :
PREFIX : <http://dbpedia.org/resource/>
The ATTEMPTO Parse Engine (APE) is now APE integrated into EulerGUI Semantic Web tool (see above Working with controlled (formal) english : ATTEMPTO ACE ).
This is a basic integration, and follows the same logic as other non N3 sources.
It means that one can create or open an existing ACE file or URL (with the file suffix .ace or .txt ).
Then one edits it in the editor (click on button "ORIGINAL") . When saving
the file (with Control-S), the executable ape.exe (which must be
in the path) is automatically launched with the arguments:
-solo owlxml <file.ace>
Then the APE output is visible by clicking on the leftmost button <file.ace> , as an N3 file.
Since this N3 is part of the current EulerGUI, it is available to the rule engines.
As for a "real" OWL or RDFS file, adding an ACE to the project also triggers the generation of rules from the OWL statements, and the SWRL, if there is some.
As a icon for APE, the ACEWiki icon is reused: ![]()
Note that using lexicons taylored for each vocabulary like it was presented at CNL 2012 would require more "GUI sugar" .
Also, the base URI used by APE currently cannot be specified .
Errors are presented in a crude way by a popup.
No completion is available in the editor at the moment. But certainly some of the code in ACEWiki could be reused. Anyway completion is not available at the moment in the EulerGUI jEdit editor for any syntax, but it is on the Roadmap for EulerGUI .
THIS IS WORK IN PROGRESS.
We already have with the Déductions form generator a means of leveraging OWL models. But now writing a model becomes a bottleneck in the software process. The N3 language is much more compact and human readable than RDF/XML but, inspired by UML class diagrams, we come with a syntax even more compact.
Note that for all classic UML diagram editors that we know, the data entry time is much too long. This slowness is because diagram editors rely on both the mouse and the keyboard.
We are working on "UML Textual" diagrams, that is to say simplified UML class diagrams that one can type with a simple text editor or send by mail. Here is an example:
Permission-------Document-------Theme
Author----------- -------DocumentFormat<|-----HTML
<|-----Word
<|-----OO
<|-----PPT
We implement a parser with Parser4J, that interprets and translates this directly into OWL :
m:Permission a owl:Class .
m:Document a owl:Class .
m:permission a owl:ObjectProperty ;
rdfs:domain m:Document ;
rdfs:range m:Permission .
m:document a owl:ObjectProperty ;
rdfs:domain m:Permission ;
rdfs:range m:Document .
# etc ...
For the UML decorations, like cardinality and names of association ends, we thought at first about this syntax, which looks like real class diagrams:
A-------B * 2
Then we thought that this is not easy to type. So we use simply this, that is both easy to type and close to real class diagrams :
A * ----- 2 B
The same syntax applies for associations end names, with or without cardinality:
Landlord owner 1 ---- property 1..* RealEstateProperty
Also this is consistent with the idea that UMLT input should be part of a "model shell" , where one can enter model and facts line by line, while a diagram is populated at once for each line. The context of this shell will be the current class, which allows to enter properties the UML way:
Person---------------EmployementRole name: xsd:string birthDate: xsd:date
A new line clears the class context:
Order<>---Status OrderLine quantity: xsd:int
Apropos the last line, we would like to guess the type xsd:int
, based on linguistic knowledge about the word "quantity" (TODO).
Again apropos the last example, the <> stands for UML
aggregation; for UML composition we have <*> , e.g. :
House <*>----- 1..* Wall
Besides UML-ish syntax, standard N3 @prefix lines will set the
default and named prefixes, e.g. :
@prefix : <http://deductions.sf.net/ontologies/e-commerce#> . @prefix dc: <http://purl.org/dc/elements/1.1/> .
We added an input in the GUI for files having UMLT syntax, through the button "XMI/UML" . A .umlt file is translated on the fly directly into an OWL file. We would like to ouput also UML. This is work is progress.
You can find more .umlt examples here:
http://deductions.svn.sourceforge.net/viewvc/deductions/n3/models/
Model Driven Architecture is an acknowledged practice in software development. This paradigm states that a huge part of a software development cycle is in fact a reflexion on the models underlying the application code : data models, workflow models, business rules, classes relationships, code dependencies, etc.
EulerGUI provides a module to extract many informations from an existing Java classes tree, and treat these pieces information as an input in your MDA process.
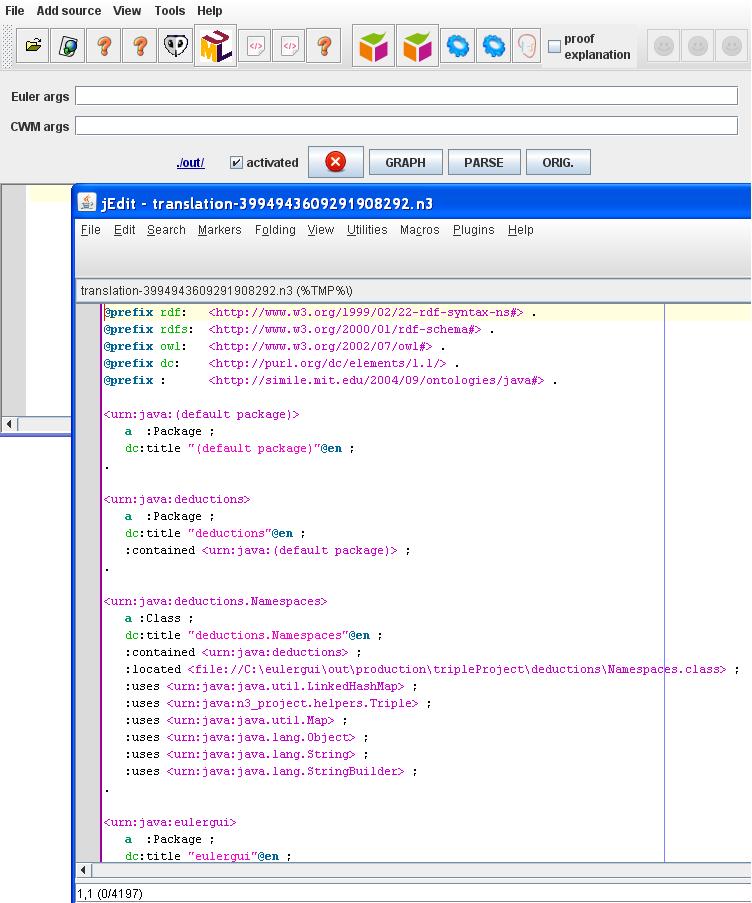
To extract information from a Java classes tree, you just have to use the "Add New Source" menu and click on "Add Java classes tree" as is:

In this example, we choose a Java classes tree available in the current directory "./out", and click "Open":

EulerGUI recursively processes the Java classes in the chosen directory (in this example, "./out") and provides a data structure, in N3 format, ready to be queried for MDA information, such as package relationships:
Once your Java code has been processed as an N3 data structure, all the processing power of N3 rules can be used to achieve queries and inference on those data. For example this query returns all methods having a parameter whose type is eulergui.project.Project :
@prefix : <http://simile.mit.edu/2004/09/ontologies/java#> .
{
?M :hasParameter [ :hasType "urn:java:eulergui.project.Project" ] .
} => {
:answer :is ?M .
} .
Underlying an N3 project, there is a stateful Drools Working Memory, we call the user Knowledge Base.
The user Knowledge Base can be visualized by two commands in the "Tools" menu.
Just after loading the project, it contains all the N3 triples from all the activated N3 sources in the project. Then, dynamically, the N3 triples from newly added N3 sources are added. Also, when an N3 source is deactivated or (re)activated, the corresponding N3 triples are removed or added.
Now when the Drools engine is launched, inference brings all consequences of the current triples in the user KB. And conversely, when an N3 source is deactivated, all consequences that do not hold anymore are removed (see paragraph Automatic retraction and logical insert ). This capability is called Truth Maintenance System (TMS) .
To demonstrate this, you can open this example : domotic.n3p . It has only one rule:
{ ?L a ns1:Light.
?L ns1:hasControl ?SWITCH.
?SWITCH ns1:hasState ?S
} => {
?L ns1:hasState ?S}.
Which amounts to say: "if the switch has a state , then the light has the same state" .
This example project has 2 data files, one with switch "On" (domotic-data.n3), the other with switch "Off" (domotic-data-off.n3). When you deactivate one of these, Drools automatically removes the conclusion drown precedently about the light.
To avoid repeating infrastructure rules and/or data, it is possible to put these in a project that will be imported as a sub-project in the main project. Any number of sub-projects can be imported. When launching one of the rule engines, the effect is as if all the N3 sources of all the sub-projects were in the main project. Adding a sub-project is achieved by clicking on entry "Import project ..." or Import project from URL..." in "File" pulldown menu.
For examples, look in the Deduction project user manual.
It is sometimes useful to launch a pipeline of projects. That is, the result of launching a project is added to the inputs of the next project in the pipeline, which is launched, and so on. This is achieved by adding a post-processing project to the current project, by clicking in relevant entry in "File" pulldown menu.
If you want to see the result of the first launch, without the post-processing project, you can deactivate it with nearby checkbox.
For example, this screenhost of the project postproc.n3p shows GUI after clicking on Drools inference button (the post-processing checkbox has been unchecked, so this is just the result of the main (first) project.

For other examples, look in the Deduction project user manual. Several example have both a sub-project and a post-processing.
First you can add one of these criteria to any Google search (thanks to Francis LAPIQUE for this trick):
filetype:rdfs filetype:owl filetype:n3 filetype:xsd filetype:uml filetype:ecore filetype:xmi , etc.
And don't forget that, once you have found something that looks good, you can drag and drop it on EulerGUI, to see it in N3.
See, related to Linked open Data: "Discovering Linked Data on the Web" , and CKAN , CKAN API .
prefix.cc is a website made by Richard Cyganiak to ease a very common task in the life of RDF developers and SPARQL users: looking up namespace URIs. A short summary of what the site can do for you is available here.
Here is a table of search engines and repositories for ontologies.
| URL | Category | Comments |
| search engine | also REST API | |
| http://swse.deri.org/ | search engine | NOT ONLY FOR ONTOLOGIES? |
| http://kmi-web05.open.ac.uk/WatsonWUI/ | search engine | also SOAP and REST API |
| search engine | also Watson | |
| Falcons | search engine | a new chinese engine; separate searches for objects, ontology, documents |
| TONES Repository | list with many columns | supports a RESTful interface;
232 ontologies |
| NCBO Bioportal | Repository | 187 ontologies actively used in biomedical communities |
| ORATE
(Ontology Repository for Assistive Technologies) |
Repository | 55 ontologies, but some are just copies from their main site; also based on Bioportal; Ruby On Rails server. |
| hit-parade | ||
| schemapedia.com | search engine | currently 277 schema referenced |
| vocab.deri.ie | Vocabularies from DERI Sem. Web research center | |
| hit-parade | ||
| tree | ||
| Repository | nice web service to find ontology URI (and hence its definition) from the N3 (consensus) prefix, and vice-versa; used in EulerGUI | |
| http://esw.w3.org/topic/SkosDev/DataZone | latest SKOS vocabularies ( knowledge organization systems (KOS) such as thesauri, classification schemes, subject heading lists and taxonomies ) |
See "Popular Vocabularies" on http://semanticweb.org/ .
Famous ontologies : "small" ones
Jow de Roo is developing a series of OWL ontologies in N3:
http://eulersharp.svn.sourceforge.net/viewvc/eulersharp/trunk/2003/03swap/index.html#ontologies
FOAF - Friend Of A Friend ; OWL
DAOP - Description Of A Project; OWL
SIOC - Semantically-Interlinked Online Communities; OWL
SKOS - from W3C, SKOS Simple Knowledge Organization System
Dublin Core _ RDFS or OWL ; dcterms : Dublin Core terms - RDFS ; dcmitype ; RDFS
Review, vCard ( this is an example of recent smart advice from W3C, by which the same URL conveys through content negotiation either OWL or HTML ).
GoodRelations - about product, price, and company
VSO - Vehicle Sales Ontology: cars, boats, bikes, and other vehicles for e-commerce
Ontologies defining ontologies: OWL.n3, RDF Schema in RDF . Ontologies defining N3 and Euler builtins : see below "CWM built-ins" and "Euler built-ins". These 4 ontologies appear in example model-rules-coherence.n3p .
Famous ontologies : "large" ones
dbPedia : for OWL download, look for "DBpedia Ontology T-BOX (Schema) "
SUMO (with MILO, etc), Dolce, BFO, UMBEL, Bremen, etc, are so-called upper level ontologies; A Comparison of Upper Ontologies .
OpenCYC is a huge ontology (Open Source), coming with its own closed-source reasoner, but I don't know how to extract domain specific sub-ontologies from Cyc.
Princeton Wordnet 3.0 in RDF : the famous and wonderful english dictionary is a way to associate an URI to word senses, thus it is a natural way for a priori understanding between applications
There a nice and updated image map about the LOD data sources (Linked Open Data), which offers the best overall view of all what is available. The same LOD sources as a table.
Currently Alive SPARQL Endpoints - the famous Linked Open Data image map graph view, the LOD as a table
http://dbpedia.org/, the SPARQL endpoint , the SPARQL Web Interface
Sindice is a nice Semantic Web search engine. It is different from Swoogle in that it searches and shows fact triples, not ontology documents. There is a nice "advanced" query where one can enter triples , e.g.:
* <http://www.w3.org/2006/vcard/ns#title> 'research'
http://sig.ma/search?q=eulergui
http://www.rdfdata.org/data.html Publicly available collections of RDF and web services that return RDF; of course the listing is itself available as RDF!
http://www.data.gov/ U.S. census data, namely all the census of the United States in 2000, representing 1 billion of triples! This triple store uses the MySQL database engine and SPARQL Sesame. It provides a query interface and some examples to train; the sparql endpoint is available at http://www.rdfabout.com/sparql ( thanks to Gautier Poupeau from lespetitescases.net ).
There is an article in the Semantic Web Journal: "Facebook Linked Data via the Graph API" . Here is an example to access public information:
eg https://graph.facebook.com/jmvanel
For accessing your private information, an access_token must be pasted from links in the facebook reference api documentation, once you are connected to Facebook .
eg 'https://graph.facebook.com/me/friends?access_token=XXX'
EulerGUI sends the right Accept-Content header for N3 or Turtle. If you use command line tools, you must explicitely add this to arguments :
curl -H 'Accept: text/turtle' 'https://graph.facebook.com/me/friends?access_token=XXX'
Otherwise you get JSON.
Google, LinkedIn: TODO
I know no rules repository or rule search engine on the Web. One trouble is that there are several formats: N3, SWRL, RuleML, RIF, Drools, Ilog, and others coming from the AI world: Prolog, TPTP, KIF, OpenCyc, ... We would like to offer translations like we do for models (currently only SWRL==>N3 and N3==> Drools).
The Euler Prolog engine (integrated in EulerGUI) can use rules in N3 logic for most of OWL concepts, see on Internet the documents owl-*.n3 in
http://eulersharp.svn.sourceforge.net/viewvc/eulersharp/trunk/2003/03swap/?sortby=file#dirlist
For example owl:differentFrom is implemented in owl-differentFrom.n3
; which reads:
@prefix owl: <http://www.w3.org/2002/07/owl#>.
{?A owl:differentFrom ?B} => {?B owl:differentFrom ?A}.
You can drag and drop this URL in an EulerGUI project.
owl-rules.n3 includes all such rules for single OWL concepts (slightly modified from the original owl-rules.n3 by Jos De Roo from the Euler project).
It also includes validity constraints, e.g. :
{?P a owl:FunctionalProperty. ?S ?P ?X, ?Y. ?X owl:differentFrom ?Y} => false.
{?A owl:differentFrom ?A} => false.
These rules implement the OWL 2 RL profile.
Also from the Euler project, there are the rdfs-rules.n3 .
An example with a business rule from FaceBook and the OWL Symmetric Property rule is here: facebook.n3p . You can drag and drop this URL to download the whole EulerGUI project.
The "Open Mind Common Sense" project is very interesting, because it asks questions about the users's sentences in plain english, to precise the inferred meaning. The database content is available as RDF.
The local tools are buttons in a row for each N3 source.
Click on the GRAPH button near each source URL : a new window pops up with the dotty graph displayer/editor from the GraphViz project. With the button in the top righ of the frame, it is also possible to display a graph of the inference result.
Example for rule BloodPressure.n3 :
{ :BloodPressure :val ?x.
?x math:greaterThan 70
} => {
:Service112 :alert "true"
} .

Legend
:alert here)dotty , with its old-fashioned look, is still a nice tool, allowing to modify the graph, save it to many formats, etc (see dotty guide ).
CAVEAT
Blank frozen Graphviz windows have been reported for Graphviz version 2.16, and it is recommended to use version >= 2.18 .
Beware, on Linux the pulldown menu in dotty does not work if the NumLock key is activated (GraphViz bug 524).
Click on the PARSE button near each source URL.
For N3 documents originating from the conversion or import of other formats (RDF/XML, XMI, plain XML, XSD, SPARQL queries, ...), the leftmost button always shows the N3 document that was translated on the fly into a local temporary file, to be fed to the inferences engines. To see the original documents, push on the ORIG. button.
NOTE
In the case of documents coming from a server doing content negotiation, like http://xmlns.com/foaf/0.1/, the original document shown the ORIG. button may be different from the original RDF source. In this case the original document is the HTML view of the URI (because it is loaded directly by the editor jEdit).
In EulerGUI there is another style of queries, called search. There can be as many searches as you want in an EulerGUI project. The search is decoupled from the inference; it searches the facts currently in the knowledge base, be it the initial facts, or the facts inferred after one or more inference launch. It's like a SPARQL query on the project, but the syntax is N3.
A search translates a query in N3 syntax as a Drools query.
By comparison, the original N3 queries are translated by Drools rules that
produce only objects of class TripleResult, which do not
participate in the inference. With the technology of original N3 queries, the
result return was completely linked to the process of inference, and there is
only one query per project. It is a legacy of Euler processor in Prolog (always
present), which does not support the "truth maintenance" ( stateful session in
Drools ).
This means that with Drools behind, you can add or remove assertions, and
all consequences of the rules is updated after a call to
fireRules.
I don't give up objects TriplesResult added to the facts, because there is existing code that depends on it. But ultimately it will simplify things for both forms generated and for the new Web server, and for application export.
LIMITATIONS
The parameter could be annotated in the N3, like this:
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix ded: <http://deductions.sf.net/n3/> .
?blog a ded:Parameter.
{
?x foaf:name ?name .
?x foaf:weblog ?blog .
} => {
?x foaf:name ?name .
?x foaf:weblog ?blog .}.
N3 searches : appearance in the GUI
To create an N3 search, push the second button with a question mark. The buttons for search are different from the unique query orange button, they are green. without "activated" checkbox, but with the "remove" red cross. The SEARCH button on right launches the search, whose result appear in the result panel below.
EXAMPLE

One enters SPARQL 1.1 Update text and endpoint in a new window with a jEdit editor for SPARQL text.
TODO :
To launch the Pellet OWL
reasoner successively on all OWL documents in the projects, click on pull-down
menu "Tools" / "Launch OWL reasoner". Not only documents with suffix
.owl are processed; documents from all origins are also
processed.
As an example, take this project: koala.n3p ; the three classes in red on bottom are unsatisfiable in this example.

Nice features (see video "EulerGUI minimum" on YouTube )
New Feature: input form generation
Clicking on a class in this tree view brings an input form for an instance of the class, using rules from Déductions project, see "Generated Swing applications".
It allows to see the properties directly connected to a class, by properties' domain and recusively by RDF sub-class relations.
TODO
Currently it is not otherwise connected to the current EulerGUI project, and the data entered in the form are lost..
When clicking on "Export as XML" in the File pull-down menu, all N3 sources
are exported as plain XML files in the xml-export directory in the
current directory. The details about the conversion from RDF to plain XML are
above in XML import: Gloze. The inference engine
result, if any, can be exported as XML by clicking on the third "smile" button
on top right of the window.
An example of a project exportable as XML is kml_n3.n3p . This example is contrived, as the N3 in the project was actually made from an XML file.
A typical use case is:
Once this has been developed in the GUI, the project (minus step 1) can be reused in any Java application by adding a few lines of code (see Using the EulerGUI API).
The steps 3. and 4. can possibly be made in a pipeline of projects (post-processing project) .
See below external tools form converting RDF/N3 to other formats : Export from N3/RDF .
The general procedure to export N3 sources (or an EulerGUI project) into any
file format is the following. First, fill the semantic gap by one (or several)
N3 rule base realizing a transform of graph structures. Then the final step
consists of applying the e:format builtin ( currently only in
Euler engine ), to output the desired character string . The e:format builtin
has as subject a list, whose first member is a format string, and whose
remaining members are arguments to the format string. The format string is the
one used in Yap
Prolog's format predicate. The object is calculated from the subject. So
one can use logical rules as a template engine like Velocity or FreeMarker to
generate any file format.
There is an N3 example of using e:format
(run it with Euler engine and --pass ).
See ideas for a quite generic RDF exporter on the Jena list.
In tools menu, the is an action to add all refered ontologies (in all N3 sources recursively in sub-projects) to current project.
This is particuliarly convenient to consult the documentation of refered ontologies, and also in in conjunction with the Launch OWL reasoner tool.
What is it ? It is an interactive way to work with the Knowledge Base in command line mode. With the N3 shell it is possible to enter triples, rules and queries. Most languages have their interactive loop: Python, Scala, Perl. So the N3 shell is an interactive loop for the N3 language.
Java does not have an interactive loop, but with the JavaScript, Jython or Groovy interpreters, the functionality is there. And now with N3 shell plus the interpretation of Java instantiations and calls in N3, Java has one more interpreter.
The N3 shell is in menu "tools".
Here is a an example of a session; note that rules can be dynamically added :
==> { :a :a :a } => { :b :b :b } . ==> :a :a :a . ==> :b ?X ?Y . FactCount: 3 <http://user-input/b> <http://user-input/b> <http://user-input/b> .
User input is in green : a rule, a fact, and a query. The first 2 lines can be reversed; that is, rules can be entered after facts. These test classes should give you an idea of what works in the N3 shell :
Note that after starting the N3 shell, rules are not fired until a triple (or a comment) is entered. Then afterwards rules are fired at each line entered.
When using N3 shell, the windows created in the session are disposed upon exit.
The JLine library is used for completions with the tab key, like bash does, e.g. these strings are completed:
"@prefix", "owl:", "rdf:", "rdfs:", "foaf:", "dc:", "log:", "string:", "list:", "eu:"
The N3 shell is using the JLine library for completion, history, like a real Unix shell.
To add add commands to the shell in N3, the framework has all what it takes to do it, even at the user level.
If one knows the Java calls that will trigger the desired action, just add a rule like:
:session :myCommand ("argument1" "argument2") => { Java calls ... }.
The way to makes Java calls is explained here : interpretation of Java instantiations and calls in N3 .
Such rules defining N3 commands, just like any rules, can be entered in :
As examples of features that can be implemented as commands in the N3, we have : open another instance of EulerGUI; open N3 editor, execute system commands (bash on Linux, cmd on Windows).
Features TO IMPLEMENT: command history, save command history.
The N3 shell is also a separate (non-GUI) program, that you can start it with :
java -cp eulergui-1.10-jar-with-dependencies.jar deductions.runtime.BasicRuntimeShell \ myProject.n3p
or:
java -cp eulergui-1.10-jar-with-dependencies.jar deductions.runtime.BasicRuntimeShell \ --pass mySource.n3 ...
So the arguments are the same as EulerGUI, which themselves are compatible with Euler.
The N3 user preferences file in N3 is in
$HOME/.eulergui_preferences.n3 . It can be edited through the
"File" Menu .
There are settings in the default content that can be uncommented. For example one can set the EulerGUI language to be different from the system language.
Through the user preferences, one can add add features without changing EulerGUI's Java code and recompiling. The preferences file in N3 offer features like Eclipse extensions points and Spring and Guice dependency injection. The extra advantage is that you can have rules adding intelligence, and, being built on a dynamic (stateful) Knowledge Base, it can react to events and property changes.
See a tutorial in another page : configure EulerGUI in N3 .
When this feature is launched, if all properties and classes are not declared, a new N3 file is added to project, with a skeleton ontology for missing declarations.
The generation rules look in the whole current projet for undeclared
properties and classes in plain data triples (individuals), incomplete
declarations and rules. The generation rules consider that a property or class
is incomplete if it has no rdfs:comment , or if the comment has
the (generated) value "???" .
For instance, from this book.n3 example:
@prefix : <http://example.com#> . :DiamondAge :writeBy :NealStephenson . :Neuromancer :writeBy :WilliamGibson . :NealStephenson a :scifiWriter . :Neuromancer a :book . :DiamondAge a :book . :MazeOfDeath :writeBy :PhilipKDick . :WilliamGibson a :scifiWriter . :PhilipKDick a :scifiWriter . :PlayerOfGames a :book . :Ubik a :book . :MazeOfDeath a :book . :PlayerOfGames :writeBy :IainBanks .
this skeleton ontology is generated:
ns1:book
a owl:Class ;
rdfs:comment "???" ;
rdfs:label "book" .
ns1:writeBy
a rdf:Property ;
rdfs:comment "???" ;
rdfs:domain ns1:book ;
rdfs:label "writeBy" ;
rdfs:range ns1:scifiWriter .
ns1:scifiWriter
a owl:Class ;
rdfs:comment "???" ;
rdfs:label "scifiWriter" .
The generation rules also guesses the domain and range, if at least one triple provides evidence. As a side effect, it downloads all refered Ontologies to current project, but does not add them to the project (they are just put in the N3 cache).
The process is incremental. Everytime you document a property or class, you modify the generated rdfs:comment, and it will not be re-generated the next time. The whole process can be called "design by example".
Activation
This feature is launched by the "Tools" menu.
In addition, this feature can also be launched whenever an N3 Source is
saved. To activate this uncomment this line in method
addDefaultProjectListeners() in class ProjectGUI :
// project.addProjectListener( new N3SourceCheck() );
See "Documenting a rule base with EulerGUI". We hope to include later other logical and quality checks on rule bases, data bases, and ontologies, like orthographic checks
Explore Semantic Web with EulerGUI
If the N3 view of an ontology is not enough for you, you can open it with Protégé 4.1 . Protégé can read N3 facts (without rules). You can also drag-and-drop an URL on Protégé. I tend to prefer writing N3 to create an ontology, and using Protégé to visualize it. In the reverse direction, to use in EulerGUI an ontology created in Protégé, simply add it to the project (saved in Protégé in N3 (Turtle), or RDF, or in OWL/XML format). EulerGUI watches the files in projects, so whenever a file is modifed in Protégé or another tool, it is re-translated into N3 if necessary.
Protégé is a wonderful and almost dominant tool for editing OWL ontologies. It comes with many useful plugins, e.g. for SWRL rules, ACE View for Controlled English, etc. So we try to be a complement to Protégé, not a concurrent. We would like to offer some or all of the EulerGUI features in Protégé, but the time for writing the glue code for eclipse style plugins is missing. But when we will generate eclipse style plugins, we will try to make it with a rule based architecture, following the ideas of the Déductions project's "Intelligent Modularity".
The notion of project used to exist in Protégé 3. In Protégé 4 there is no notion of project, you just import OWL ontologies into the main ontology with standard OWL import mechanism. So one could export an N3 project as a main ontology importing the N3/RDF sources (but the non RDF sources would have to be translated once for all). The N3 rules should be translated to SWRL rules (FEATURE NOT IMPLEMENTED).
In the reverse direction, when using an ontology from Protégé in EulerGUI, the imported ontologies should be added to the current EulerGUI project (FEATURE NOT IMPLEMENTED).
We are working on a new N3 format for EulerGUI projects to replace the current XML encoder based format, see project_ontology ; this format will as compatible as possible with Protégé 4 .
Several important plugins are still only in Protégé 3.4.X, especially the Jess bridge.
In Protégé 4, the SWRL input in found in View / Ontology views / Rules. During a classification execution with Pellet, the rules are taken into account, complying with a subset of SWRL called DL safe (but as of july 2010 Pellet does not implement SWRL builtins).
In addition to the SWRL specification, the SWRL Language FAQ by Martin O'Connor is worth reading.
SWRL rules are stored in OWL/RDF, in the same document as the OWL ontology that they complement . SWRL rules obey to an OWL ontology . An OWL ontology for SWRL is swrl.owl. Here is an image of this ontology for SWRL in Protégé OWL editor :

The differences between SWRL and N3 rules are:
There is a Translator from SWRL to N3 logic implemented in N3 logic. It is embedded in EulerGUI, and the source is also available from an URL.
What is implemented :
For every day a man sees a woman.
day(?x1) -> man(?x2) ∧ (see some woman)(?x2)
Every carnivore eats every meat.
carnivore(?x1) , meat(?x2) -> eat(?x1, ?x2)
large(?X) -> price(?X, 10)
If you want to run the SWRL to N3 translator manually take this project : test_swrl_to_n3.n3p . You can also have a look at the N3 rules of the translator here:
The translator is automatically launched when an OWL source
has SWRL rules, and the translated N3 rules are added to the project, for each
OWL source having SWRL rules. That is, for a source named XXX.owl,
the generated N3 rule base is XXX.owl.as.rules.n3 .
You can try this with this small project : swrl-n3-rules-owl.n3p .
Then you can run any of the inference engines in EulerGUI, and the SWRL rules will be taken in account just like any N3 rule.
Running the project with the Euler Yap (EYE) engine, or Drools/N3 engine fires the BadChild rule and gives :
:bc a :BadChild.
In the case of the Drools engine, the N3/RDF/OWL Knowledge Base is stateful and dynamic. This means that every time you fire rules with the Drools button, all consequences of new facts (and new rules by the way) are added to the KB.
Also, upon dragging and dropping onto, or adding to the project, an OWL document with SWRL rules, the translation from SWRL to N3 logic occurs, and this adds to the project a temporary N3 document containing the rules. The SWRL to N3 translation is re-done every time a project with an OWL-SWRL source is opened.
Opening this larger example
project with dl-safe.owl adds to the
project the N3 document dl-safe.owl.as.rules.n3, which contains
these N3 rules :
{?t0 a :GoodChild} => {?t0 a :Child}.
{?t0 a :BadChild} => {?t0 a :Child}.
{?t0 a :Grandchild. ?t0 :sibling ?t1. ?t0 :hates ?t1} => {?t0 a :BadChild}.
The SWRL rule come from this small OWL + SWRL example: http://owldl.com/ontologies/dl-safe.owl .
Opening the document in Protégé allows to see the rules in SWRL syntax, e.g. :
Grandchild(?x) , hates(?x, ?y) , sibling(?x, ?y) -> BadChild(?x)
Other examples:
The "official" list of Implementations from ESW : http://esw.w3.org/SparqlImplementations
RAP NetAPI - An RDF Server for PHP
Please refer to this how-to for starting an SPARQL server (end-point) serving data from the native RDF base TDB, and making use of the Pellet OWL reasoner: Configuring Joseki + Pellet + TDB .
In fact we provide a shorter How-To. We will create a blank database that will be populated via the SPARQL/Update protocol.
Add this bold term in in script bin/make_classpath at line
41:
for jar in "$LIBDIR"/*.jar lib-tdb/*.jar
If you prefer, you can activate the RDF graphs from anywhere by changing the configuration joseki-config-tdb.ttl:
# Parameters - this processor processes FROM / FROM NAMED joseki: allowExplicitDataset "true" ^ ^ xsd: boolean; joseki: allowWebLoading "true" ^ ^ xsd: boolean;
Then we can launch the server:
export JOSEKIROOT=$PWD bin/rdfserver joseki-config-tdb.ttl
Now we can populate the database via the SPARQL / Update protocol : send a POST request to the URL: http://localhost:2020/update/service with the content:
LOAD <http://aims.fao.org/aos/cwr.owl>
You can install in Firefox the RESTClient plugin to send arbitrary HTTP requests.
You can also load a local file, not necessarily in RDF / XML format :
LOAD <file:///home/jmv/ontologies/foaf.n3>
Look here for how to use EulerGUI to launch and save SPARQL queries: SPARQL queries as N3 sources. The SPARQL "endpoint" is : http://localhost:2020/sparql .
It would be nice to export an EulerGUI project as a Joseki configuration . Each data source could be stored in Joseki. In fact, we can either generate a configuration Joseki in N3 or generate SPARQL / Update queries that will create the database for a server (empty or not). When there will be project files in N3, option 1 will be easy to implement.
http://mondeca.wordpress.com/2008/04/05/how-to-install-a-sesame-rdf-server/ : not updated to latest Sesame 2.3 .
You can wrap an existing relational database in a SPARQL server. A classical tool for that is D2R. When setting up D2R for your relational database, it proposes a generic mapping between the relational schema and a generated OWL ontology; You can adapt the default mapping to your needs. There is also D2RQ (SPARQL 1.1 support).
Another tool is Protégé's plugin DataMaster, which imports schema structure and data from relational databases into Protégé.
This paradoxical expression refers to the latest offspring of EulerGUI. It is not, at the moment, EulerGUI's GUI having server capabilities. It is a REST HTTP server, implemented as a Maven project dependent of EulerGUI, that exposes an EulerGUI project with its expert system (rule engine) features. There is a wiki page on EulerGUI server.
There is a shell script for demonstrations (suitable for Linux or Cygwin): demo.sh , with a Windows version: demo.bat .
Hopefully we will soon have a video made with Wink or another tool.
eulergui --pass my.n3
( since EulerGUI understands a single argument as a project file or URI )
Search / Find ... menu in jEdit editor
See a comprehensive list in Getting started .
To see simple examples of Euler GUI projects:
Find others in Déduction project - Java Swing application generator from OWL model and N3 logic rules
These links point to the Sourceforge repository; you can drag'n'drop the links to the middle gray zone (underneath "CWM args"), or by clicking File / Open project from URL.
You can also click on "Download GNU tarball" to download the whole directory, at the end of the page.
Tools lists:
Recommended tools (only Open Source tools) :
Triple stores (Open Source)
RDF API for different programming languages:
Rules engines
Prova (Prolog like, in Java)
The syntax of the rule language (DSL) : Ferrari ; the language is in fact pretty similar to Drools in its semantics.
http://esw.w3.org/topic/ConverterFromRdf
EulerGUI enables export from N3/RDF to any XML format that has an XML Schema description. It is not automatic (and cannot be easily). The procedure is: convert the XML Schema into OWL to see what should be generated; define rules to translate or annotate your RDF vocabulary of classes and properties; run one of EulerGUI rule engines on your data plus translation rules; export the result as XML using the yellow button on the upper right corner. TODO : add an example <<<<
See above: Export as XML ; XML import: Gloze
n-triples2kif.pl An RDF processing tool; converts n-triples to KIF ( Knowledge Interchange Format )
perl n-triples2kif.pl <foo.nt > foo.kif
http://esw.w3.org/topic/ConverterToRdf ( EulerGUI is there in the list ! )
http://simile.mit.edu/wiki/RDFizers ( JPEG, Subversion logs; Simile is a most interesting project)
The N3 language, that allows to express facts, classes and properties, and rules, is a convergence language in whose format every data format is translatable. It is "isomorphic" to RDF, that is, one can translate back and forth without loss of information. It is also much more human readable than RDF. There is a version of the RDF primer where every example is in N3, so much more readable than the original above mentionned.
N3 has several sub-formats, ordered below with more and more expressive power and syntaxic sugar :
Tutorials:
Primer: Getting into RDF & Semantic Web using N3 : recommended
A Rosetta stone of different formats: N3, Prolog, SQL, javascript, ...
Practical Rule Engines, a presentation on rule engines (from a Drools point of view)
In EulerGUI site:
Books:
this is not about N3 rules, but its is a practical oriented book, and it is quite easy to translate examples in N3 (if you have some material we'd be glad to add it to EulerGUI site )
the most widespread book for teaching Artificial Intelligence; read chapters about logics, forward and backward chaining, etc
The specifications:
http://www.w3.org/TeamSubmission/n3/ ( W3C Team Submission 14 January 2008 )
Notation3 (N3) A readable RDF syntax ( preceding document )
http://www.w3.org/DesignIssues/N3Logic; some corrections to this document on the EulerGUI site: N3Logic
Article in "Theory and Practice of Logic Programming" : N3Logic: A Logical Framework For the World Wide Web, by Tim Berners-Lee, Dan Connolly, Lalana Kagal, Yosi Scharf
Builtins documentation
http://www.w3.org/2000/10/swap/doc/CwmBuiltins; CWM Builtins are defined in N3 in log.n3 , math.n3 .
The Euler specific builtins are defined in N3 in log-rules.n3 .
Some functions from the XPath functions namespace ( http://www.w3.org/2005/xpath-functions# )
are implemented in Euler : resolve-uri , substring , substring-after ,
substring-before .
Euler proof engine accepts rules in Coherent Logic Form i.e. basically
conjunction => disjunction of conjunctions, including existential terms.
Any First Order Logic formula can be rewritten in such a way.
Coherent Logic is well suited to object creation.
See rpo-rules.n3 and search for "=>" in the examples above.
An example with disjunction (logical or) in the consequent is here in the EulerGUI source tree :
About Coherent Logic, see the last chapter of
http://folli.loria.fr/cds/2006/courses/Bezem.Nivelle.IntroductionToAutomatedReasoning.pdf
Geolog and Skolem Machines - John Fisher, Marc Bezem
CWM built-ins are described here:
http://www.w3.org/2000/10/swap/doc/CwmBuiltins
The builtins implemented in the EulerGUI Drools N3 engine are in bold.
The following bring a form of negation into N3 logic.
log:notEqualTo Equality in this sense is actually the same URI. Do not confuse with daml:EquivalentTo. A cwm built-in logical operator. log:notIncludes The object formula is NOT a subset of subject. True iff log:includes is false. The converse of log:includes. (Understood natively by cwm. The subject formula may contain variables. (In cwm, variables must of course end up getting bound before the log:include test can be done, or an infinite result set would result) Related: See includes
The Euler specific builtins are defined in N3 in log-rules.n3 and euler-builtins.n3 . They now include all the RIF builtins.
Below, the builtins implemented in the EulerGUI Drools N3 engine are highlighted.
The following predicates bring a form of negation into N3 logic (see also Bypass Semantic Web limitations in "N3 rules: good practices, design patterns, refactoring" ).
e:findall a rdf:Property;
rdfs:comment "builtin that (?SCOPE ?SPAN) e:findall (?SELECT ?WHERE ?ANSWER).
unifies ?ANSWER with a list that contains all the instantiations of ?SELECT satisfying the ?WHERE clause in the ?SCOPE ?SPAN of all asserted n3 formulae and their log:conclusion";
rdfs:domain rdf:List;
rdfs:range rdf:List .
e:notLabel a rdf:Property;
rdfs:comment "builtin to test wether the subject is not a blank node with label in object (this is a level breaker)";
rdfs:domain rdfs:Resource;
rdfs:range rdfs:Literal .
e:optional a rdf:Property;
rdfs:comment "builtin to call object formula and to succeed anyway";
rdfs:domain rdfs:Resource;
rdfs:range log:Formula .
kb:retract , kb:replaceValue ;
see respectively test/builtins.n3 , form-rules.n3eg:trace ; see n3_rules_good_practicesDrools is a forward chaining engine in Java, using the famous RETE algorithm. Compared to a full First Order Logic engine like Euler SEM or Prover9, there is a loss in expressivity:
But there also advantages:
This paragrapth describes the basic mapping of pure N3 rules to Drools. For extended N3 rules , involving Java object within the N3+Java Knowledge Base, see this paragraph : Interpret Java instantiations and calls in N3 sources .
Here is a test I did with Drools before writing an automated transform for EulerGUI. The only rule was this one, defining what an OWL Transitive Property is, taken from rpo-rules.n3 from the Euler project :
{?P a owl:TransitiveProperty. ?S ?P ?X. ?X ?P ?O } => {?S ?P ?O}.
I did a hand translation into Drools of this N3. One can see that N3 is more compact than Drools . An annoying thing is that implicit variable binding is not allowed in Drools, which makes it less declarative than N3 and Prolog, and complicates the translation.
package com.sample import com.sample.DroolsTestTriples.Triple; rule "OWL transitive property" when // this design works but is not well adapted to automatic translation, // because in Drools there is variable declaration and then variable reference Triple( $P: subject , predicate=="a" , object=="owl:TransitiveProperty" ) Triple( $S: subject , predicate == $P, $X: object ) Triple( subject == $X , predicate == $P, $O: object ) // trying to split variable declaration and variable reference // but Drools doesn't allow yet implicit variable binding // cf chat with Mark Proctor 2008-11-09 :-( /* Triple( $P == subject , predicate=="a" , object=="owl:TransitiveProperty" ) Triple( $S == subject , predicate == $P, $X == object ) Triple( subject == $X , predicate == $P, $O == object ) */ then insertLogical( new Triple( $S, $P, $O ) ); end
This Drools code refers to a small Java class Triple, with 3 string properties: subject, predicate, object, that is put in Drools' "working memory". Drools must be configured to insert objects by testing uniqueness with equals(), not by object Id (the default); Triple.equals() is implemented as equality of subject, predicate, and object . The actual automatic translation uses full URI's , e.g. the first bold line above is actually :
Triple( $P: subject , predicate == "<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>" ,
object == "<http://www.w3.org/2002/07/owl#TransitiveProperty>" )
so that Triple does not have to deal with N3 prefixes.
In addition to this simple pattern, something has to be done for variables existentially qualified in the consequent of an implication. Which means, in ordinary developers' language, instantiation. Here is an example:
{ ?MEAL :mealType "french" } =>
{ ?MEAL :hasDessert ?DESSERT }
which means "a meal of type "french" has a dessert". Then the implementation must ensure that:
For point 1, we just increment an instance number at runtime.
For point 2, given the uniqueness with triples' string representation in Drools storage (see above), there cannot be more than one value for a subject and a predicate.
This uniqueness in Drools storage means we can say such things:
:jmvanel :ate :apple_pie . :jmvanel :ate :apple_pie .
but it will be just the same as saying it just once . I don't think this is a severe limitation.
Suppose a rule base with a single rule saying "if the switch has a state, then the light has the same state".
{?L a ns1:Light.
?L ns1:hasControl ?SWITCH.
?SWITCH ns1:hasState ?S
} => {
?L ns1:hasState ?S }.
When changing the switch's state, it is desirable to avoid having to explicitly remove the lamp's old state.
And this is achieved using Drools' insertLogical() feature in the consequents. Drools' insertLogical() does truth maintenance; it retracts objects automatically when there are no more facts to support the truth of the currently firing rule.
This feature is activated by default in the GUI (it can be switched off in the API).
Examples: domotic.n3p , acceleration_form.n3p
The example just above should be written this way, because the _ prefix is just exactly the way to denote existential qualification.
{ ?MEAL :mealType "french" } =>
{ ?MEAL hasDessert _:DESSERT }
But this is not currently implemented for the Drools engine. Neither is this equivalent N3 syntax, that avoids altogether the need for an existential variable:
{ ?MEAL :mealType "french" }
=>
{ ?MEAL :hasDessert [ ] } .
EulerGUI is more than a Integrated Development Environment, it is a framework to build rule-based applications on several platforms; see Overall diagrams .
A very important point for the quality of the software is the separation between business logic and platform aspects (i.e. persistence, network, GUI). Precisely the rule-based formalization allows a radical separation between business and implementation.
A key point is that you don't have to generate (Java) business classes from model (ontologies); business data are represented as RDF triples in memory and on storage, and rules are interpreted by a rule engine. So the business model and rules is completely out of the procedural (Java) code.
Let's review the advantages compared to a traditional development:
This is on top of the known advantages of Rule Engines and Experts Systems:
The main uses of the FRAMEWORK are:
The code written by hand that remains is :
Point 1 has to be implemented by hand, but in many cases it amounts to retrieve the recursive closure of order 1 or 2 from a resource(s) of interest. To automatize this, we need to design and implement a backward engine for querying SPARQL databases; it will generate a big SPARQL query by recursively accumulating criterium terms, substituting bound variables, renaming variables if necessary (see SPARQL generation).
For point 2, data persistence, one can use one or more simple generic rules, coupled with updates with SPARQL 1.1.
Note that point 3 has already some helper rule base ( see Rule based Swing applications ) .
See next paragraph, and separate pages :
EulerGUI is more than a Integrated Development Environment, it is a framework to build rule-based applications on several platforms. Having already ontologies and possibly rules in OWL, SWRL, N3, or ACE, he workflow is :
There is a lot of flexibility for deployment of an EG runtime; see this companion page "Deployment of an EulerGUI runtime" .
Other background :
EulerGUI JavaDoc ; EulerGUI application building Framework
Running Drools engine on a project
The most simple call sequence (stateless) is :
Project project = Project.restore( new URL(projectURL) ); List<ITriple> result = project.runDroolsTriples();
The corresponding test class is TestReasonning.
Running a dynamic (stateful) Drools engine
There is a facade and executable class to start a Rule Based Application with the EulerGUI framework, RuleBasedApplicationStarter . Here is how to bootstrap, assuming the internal rules and ontologies are an EulerGUI project in the classpath :
URI RULES = new URI ( "myProject.n3p" ); Project project = ProjectFactory.restoreAny( RULES, /*inactivateListeners*/true ); RuleBasedApplicationStarter appStarter = new RuleBasedApplicationStarter(); ITripleJavaStore tripleStoreRETE = appStarter.startFromProject(project);
Here are typical usages, assuming we are inside an event loop. Typically
there is an event loop, calling fireAllRules() at every event,
because this call is not expensive in CPU.
In a Swing based application (like the generated forms in Rule based Swing applications), the event loop is the AWT
(Swing) event thread. In this case, generic listeners for focus lost and
buttons events are set, which translate the events into N3 triples, assert them
in the KB, and call fireAllRules() , see runtime
architecture callbacks .
We can add various N3 sources, by URI, file, or string like here :
appStarter.addKnowledge( new N3Source( "http://myURI/", ":x :p :v.") );
With the ITripleStoreRETE object (alias KB), you have total
control on adding, removing, updating triples, launching inference, and query ;
for example:
// adding an RDF triple in N3; the N3 syntax is used for each term, for instance here a string literal is between ""
tripleStoreRETE.store( new Triple("_:s", "_:p", "\"value\"" ) );
// launch a search that is in the KB
List<ITriple> triples = tripleStoreRETE.query( "./query.n3" );
// launch a search from an N3 query string
triples = appStarter.searchFromString( "{ ?S _:p ?V } => {}." );
Some example sources are in:
https://deductions.svn.sourceforge.net/svnroot/deductions/samples/contact_table
One can consider a forward chaining rule engine like the Drools based
ITripleStoreRETE object like a very flexible MVC
framework. The KB is both the Model and the Controler. The Model part
are the facts inserted in the KB: triples for business facts, ordinary Java
objects for the infrastructure . The Controler part are the rules, both
business rules manipulating business facts, and mixed rules querying business
facts and changing Java objects on the consequent side (LHS) of the rules. And
the View is constituted of whatever changing Java objects appearing on the
consequent side ( see video in french about the
EulerGUI framework ) .
Internally, RuleBasedApplicationStarter currently contains this code :
Project p = ProjectFactory.restore( path ); p.prepareDrools(); p.getTranslator().copyN3factsToDrools(); ITripleStoreRETE store = TripleStoreDrools.createFromProject(p); p.getTranslator().addInfrastructureRules(); store.fireAllRules();
For more code examples, you can look the code of the N3 shell, or this example: StatefulKB.java , or the code of the EulerGUI server .
Adding an N3 source to a project
This call sequence is used when the user opens an URL, that can be anything :
SourceFactory sourceFactory = new SourceFactory(); N3Source n3 = sourceFactory.addSource( new URL(url), project );
Note: if you use plain XML sources, it is better to keep the SourceFactory as a singleton, because it accumulates the compiled XML Schema.
Then, if the N3 source is translated from another format,
n3.getFileName() will return an N3 temporary file for it. If it is
a local N3 file, it returns the local N3 file. And if it is a true N3 document
from the Web, the full URI is returned.
This is the main new feature of release 1.9 . Also known as "embedded Java objects" , this means that Java object within the N3+Java Knowledge Base react to rules in real time. It leverages on the embedded Drools forward chaining inference engine.
See details in "N3 - Java mapping" in architecture page (embedded Java objects) .
This architecture is leveraged in Rule based Swing applications .
On an architectural point of view, this is very important. We think that rules and Description Logic are better fit to business rules than Object Oriented languages. There is no need to generate POJO Java classes from the OWL model.
This feature allows to keep business rules written 100% in N3 and OWL, while other rules ("mixed rules") have Java instantiation, property or method calls in their consequence side.
This is the ultimate in keeping business logic and infrastructure and platform code separate. This good practice is recognized as cornerstone of software engineering, but it's too easy to violate when writing both business logic and infrastructure logic in Java. With the EulerGUI + Déductions framework:
For a concrete example, open the project person-app.n3p , and see details in Building Applications with the EulerGUI + Déductions framework .
This is actually Javascript code generation, but instantiating Java objects. It is not currently activated anymore from EulerGUI 1.8 on.
After an Euler run, click on pull-down menu "Tools" / "Javascript console " . Then each N3 triples matching a pattern for Java will trigger instantiation, property or method calls. This menu entry is a toggle; in this mode every time an inference engine is started, a new Java objects graph is created from the inference results.
This will trigger instantiation of a Java object :
@prefix java: <http://java.sun.com/class#> . :myWindow a java:javax_swing_JFrame .
This will be interpreted as :
myWindow = new javax.swing.JFrame();
A triple involving a Java object in first position (subject) will be interpreted as a JavaBean property, e.g. :
:myWindow java:visible xsd:true .
will be interpreted as :
myWindow.setVisible(true);
There is also a prefix for Java method calls, e.g. :
@prefix javam: <http://java.sun.com/method#> . :myWindow javam:setSize ( 300 200 ).
Note that ( 300 200 ) here is just a N3 list.
See project java_gen.n3p in the examples.
Since any Java code can be generated (not particularly Swing code), when a window is generated, it is often underneath other windows, because EulerGUI doesn't monitor this generated code.
There are two implementations of this N3 - Java mapping:
Once you have the business logic secured by rules, what is missing to make real applications ?
Generic Semantic Web aware widgets.
What widgets can be used?
see example TableApp.java
Other UI platforms are in project, like web applications, see GUI generation for web applications .
A lot a work has been done on applications generated this way through Drools engine . Here is a short list of features :
To use that in your project, just :
@prefix app: <http://jmvanel.free.fr/ontology/software_applications.owl#> .
:GUI a app:SoftwareApplication ;
app:editedClass :myClass ;
app:platform app:Java .
How To : Deduction project - Java Swing application generator from OWL model and N3 logic rules .
The example deductions_person.n3p allows to run the main "Déductions" example without explicitly downloading all the sources .
Beyond the automated applications described above, the framework allows to make custom applications , while still leveraging on ontologies and business rules, see "Building Applications with the EulerGUI + Déductions framework".
See also on Déduction site: FAQ on Déductions form generator .
Partly prioritized, mostly historical, with older ideas below.
See also N3_editor_FEATURE_PROPOSALS
HTTP response Code, when not good, for N3 sources
result statistics for N3 sources: number of triples or size; number of unique resources
eg foaf:
would download the FOAF ontology, reusing prefix.cc
{ <http://richard.cyganiak.de/foaf.n3> log:semantics ?foaf .
?foaf log:includes {?s ?p ?o} .
} => {
?s ?p ?o
} .
line details ( label - values table for the line)
add to project
open resource in new table
open resource in same table
open resource in web browser
question: how is the MIME type then ?
- show a tree view for the N3 data, similar to the one for ontologies; grouped by class, then by properties
- reformat the N3 sources in editor with Jena and / or CWM
- new N3 sources types:
* RDFa : https://github.com/shellac/java-rdfa#readme
It has a Maven repo ! http://www.rootdev.net/maven/repo/
* ng4j semwebclient
- leverage LOD specifications to facilitate data discovery (VOID ontology, etc; to explore)
See, related: "Discovering Linked Data on the Web" , and CKAN , CKAN API .
- GUI facilities for querying several search engines like Swoogle, Watson, etc
- how does a user know when a project need to use cwm, euler, fuxi or reasoner4j
if the N3 rules are specific ? there should be something like:
<> eg:preferedEngine <http:eulersharp.sf.net> .
- save user actions in an N3 file, to facilitate bug reports:
implement as a ProjectListener
- hourglass should show the eclapsed time (progress of the computation as % not possible, but CPU and elapsed times possible)
- add to project ontologies imported by owl:import, as unactivated transient sources
(use a rule in user KB)
- in Tools menu, add an action to add in project a generated file describing RDF properties used in the project's rules and other undefined properties and classes not found in refered ontologies (use existing rule base rule-documentor.n3)
- EulerGUI should flag non-monotonic (non Open World Assumption),
and non UNA (Unique Name Assumptions) rules and documents containing such rules;
implementation with N3 rules powered by Euler engine
- an N3 file with fileencoding=utf-8, fileencodings=ucs-bom,utf-8,default,latin1
is not parsed right when it contains a non-ASCII character
(add code sent by Luc)
- search for a string in (activated) N3 sources
(leverage on the jEdit's hypersearch feature : just add a parag. in doc.)
- instantiating Java objects: instead of the hard-coded stuff, use N3 rules
creating explicitly the instructions: new, method calls, and assignments;
this will pave the way for generating other languages than JavaScript
- YAML import and export (using snakeyaml)
- component based architecture with on-demand download (JNLP?, OSGi?, Maven based?);
* use Java Web Start (JNLP) , plus the Maven JNLP plugin :
http://mojo.codehaus.org/webstart/webstart-maven-plugin/jnlp-mojos-overview.html
Hopefully this would allow to download the auxiliary jars on demand,
when the user starts using the feature.
An alternative is to use OSGi; reuse the Maven configuration is possible with
Apache Felix maven-bundle-plugin and Maven SCR Plugin, see my blog on 2010-08-05
- in Drools engine, implement:
@forAll CLASS .
?CLASS app:subClassOrSameClass ?CLASS .
- BUG: test with log:dtlit does not compile with Drools,
transtype from a variable
- find how to work with rules for generating XML, especially generate
ordered lists
- guess when it is appropriate to import swing-rules3.n3 and
launch the application generator: when swing-rules*.n3p is imported,
or there is a property app:editedClass;
do so by applying rules in a KB instance dedicated to EulerGUI itself;
- give (facultative) name to projects
- edit an object graph means first visualize it; use case friendship in FOAF;
visualize object graph graphically;
the current GraphViz output is unsuitable for large models;
should apply the lens feature;
should be able to visualize also query results
- parametrized predefined (or user written) queries, e.g.:
q:class q:print_properties foaf:Agent .
in deductions/n3/print_properties_for_class.n3
generated forms could be leveraged
- make a Protégé 4.1 plugin, that would create an EulerGUI Project from the Protégé documents,
open N3 + rules files or URL, and launch one of the reasoners
- export N3 rules as SWRL; small problem: you must declare the predicates and classes,
this can be done with rules; the predicate can already be declared elsewhere in the project
- add statistics for sources as tooltips (or in another tab): # of triples, and rules
- check linguistic quality: detect misspellings, etc ...
- interface to web services for finding ontologies: http://swoogle.umbc.edu/index.php?option=com_swoogle_manual&manual=search_overview
http://www.schemaweb.info/webservices/WebServices.aspx
- search in all sources: literal, URI, blank node, or variable;
* subject, predicate, or object;
* in antecedent or consequent;
* would be good to have hyperlinks for matches like JEdit or eclipse;
with Vim this should work:
vim --servername 'myFile.n3' --remote-send ':123'
http://www.vim.org/htmldoc/remote.html
- source file management: highlight somehow the missing local files
- open one or more existing N3 files and make a project of it by D'n'D : ?
- enhance link to Pellet: also classify instances
- maintain a list of problems from Pellet, from special N3 rules)
- link to Prover9 (checked what Euler does already, but that does not work well);
- SPARQL syntax for queries (either translating to N3 queries, or reusing ARQ)
- connect to Sesame, Virtuoso databases: amounts to SPARQL access;
more to do?
- connect to JDBC database; (? mapping RDBToRDF, embed R2D as an EulerGUI plugin)
- connect to XML database (eXist), reuse Gloze mapping;
- connect to JoaFip, JPA, XMLEncoder, etc persistence;
- implement my "Proposal for a new ontology and N3 format for RDF + OWL + rules projects";
project.owl.n3
- open a form "Déductions style" for an N3 file in project;
this one is a nice feature that rises architectural questions:
* guess where are the RDFS or OWL sources that define used properties and prefixes
* have an API to launch other form generators (e.g. Protégé)
- helper for simple queries (by subject, property, or object, or by class);
- show triples as table (all triples for same class on one table,
all triples for same subject on one row);
this is both a feature for EulerGUI and Déductions generator
- graphviz view also for result
- add the inference result as a new file in the project (on user choice)
- button to export the whole project:
- as a zip file, that is, the .n3p file plus all local files refered
- as a Drools project (what is a Drools project ?)
- as Protégé OWL project
- as Prolog files
- button to export an N3 file as RDF
- button to export an N3 file as XMI
- button to export an N3 file as JSON or YAML
- add a button for old main class euler.EulerRunner ?
- add a "close all" action that will close all opened editors
- show modification status since last run, and watch file modification to restart last run
(leveragin existing file watcher URIModificationChecker, or jnotify)
- more flexibility to enter CWM parameters
- change the project file format to be N3 or RDF (instead of Java XMLEncoder today);
the implementation would not be too difficult, by reusing the infrastructure to
generate a Java object graph from special N3 triples ( there would be a N3 rule set
to translate the project file N3 vocabulary to a Java object graph
WORK IN PROGRESS, see rules in eulergui/site/rules)
- show dependency among N3 and RDF sources: some define RDFS or OWL classes, others
use them; some "define" Id's in subject position, others "use" them in object position;
also rule dependencies: some sources have property P1 in consequent, while others
have property P1 in antecedent
- write a set of rules for checking quality of OWL models, and display messages in a
convenient way
- write a set of rules for checking quality of rules, and display messages in a
convenient way;
- integrate Attempto (e.g. use the REST interface calling the ACE site)
- integrate WordNet, to propose to user correspondences between
OWL and RDF classes and WN synsets
- integrate Swoop (open Swoop on current project)
- export in common rule formats ( SWRL, RIF, RuleML, Rewerse, Prolog ... )
- import other rule formats ( RIF )
- design: introduce some light-weight extensions points (maybe using AOP ?),
or use Felix OSGi engine
- tooltips associated to resources in N3 editor with "which class", "which properties?",
"which instances?"
- tooltips showing namespaces corresponding to prefixes
- put namespace prefixes in another pane
- check URL after user enters it
- qualify N3 sources with mini-icons or button background: OWL DL, etc, N3 logic,
UML, XMI, RDF, ...
- check consistency of the project, whenever the file changes on disk)
(still need the button in case the GUI can't always know when
an HTPP URL has changed)
- provide more sensible error messages when one of the source
files/URL's is invalid (at least the file name)
- saving an N3 on the network ? Webdav ? FTP ?
- "exporting" the project as an URL-encoded string,
ready for use with Codd portal.
For that there could be an URL prefix in the GUI config.
- read RDF/OWL files through CWM with Jython (so avoids the current need to install
separately CWM)
- compare results between CWM and Euler runs
- expert system to find a suitable editor on a given machine
- put Prolog console in a console frame, not standard input/output
Starting in april 2009, features above are moved here when implemented.
- allow other simplified file paths than just ./x.n3 or ./dir/xx.n3 , namely ../xx.n3 - the open N3 and orange ? buttons, when the file is not existing, will open directly the editor, while also creating a button entry in the source list - instantiating Java objects: assert explicitly Java objects in Drools Working Memory (currently only Triple objects are asserted) - better use of multithread, to avoid slow opening of projects with large sources translated from other formats and from URL - in tools menu, add to project ontologies defined by the N3 prefixes in all sources - run external process and Drools runs in another thread, to be able to stop them - preferences (configuration) file $HOME/.eulergui_preferences.n3 which is updated with the standard N3 editor - re-use the web services at prefix.cc to insert N3 prefixes in the editor - refresh all conversions to N3 (useful if modifications in e.g. Protégé) - avoid messages on the standard output, use a logger and a message tab, especially for input errors - read OWL/XML files (with OWLAPI) : use case: read files from AceWiki - add a cache for compiled Drools rules bases (with OSCache) - help Déductions designer to choose an "edited class" in a model: show a subclass "combo" tree view - internationalization, then french localization - open one or more existing N3 files and make a project of it, by multiple command line arguments - import SWRL rules from OWL files from Protégé - link to Pellet: show OWL inferred class hierarchy in a JTree window - Generate XML from RDF: simple typical use case: XForms - import from SPARQL data sources : connect to a SPARQL endpoint, viewed as another N3 source - import XML Schema and XML documents having a Schema (or not), by using Gloze add-on to Jena, and ReDeFer project - Generate XML from RDF: typical use case: XForms - add Fuxi CWM compatible rule engine - load project file from an URL - project pipeline and project import - reading and translating to N3 an UML or EMF eCore XMI file - use parser4j in Drools engine, Graphviz and generated application; - import a project into another project - allow simplified file paths ./x.n3 , ./dir/xx.n3 this will make N3 project directory more manageable by splitting them into sub-directories
EulerGUI is some way a laboratory for a new rule-based way of developping applications. So some features will be tested in EulerGUI itself, and some in other applications based on the framework. There are others tasks relativement independant:
Not prioritized:
EulerGUI 2.0
| Features
and code changes |
Comments | Estimate
(skilled developper) |
Sub-feature | Sub-feature |
|---|---|---|---|---|
| modularize EG: extract first large dependencies like UML and eCore, then GUI stuff, thus having a bare eulergui-core with mostly framework API (including Drools compiler), and eulergui-light | split code in Maven modules | 2 | ||
| switch to Scala branch as main branch | refactorings like move are needed for modularize | 1 | ||
| new N3 projects OWL compatible | can entail lots of simplifications, using reactive mixed rules, but lots of changes | 4 | show project metadata (rdfs:label, etc) in tools menu | set SPARQL endpoints for queries, and for storing (also set in global configuration) |
| extension points for adding features in N3 configuration file | will also enable many things: user defined extension points à la eclipse; several user modes ; this will also be similar to Spring configuration, but with possibly platform and context -aware rules here; estimation just for creating interfaces and containers in Java | 2 | new N3 sources types: RDFa, ATTEMPTO sentences, ng4j / semweb client | |
| integrate as a tool the rule base checking for undeclared properties and classes | Feature: add to project the skeleton ontology;
implementation : add temporarilly a sub-project, and remove it after running |
1 | ||
| generic semantic web aware GUI components |
|
|||
example application: FOAF editor with:
|
this can go a long way, and is suitable for a student project;
additional features: completion for strings; import contacts from
Google API's;
NOTE: with different underlying ontology, features are also needed for a musical player application |
4 | ||
| use internal KB for adding simple useful features, based on internal events on the Project | depends on extension points ; possible features: statistics about each N3 source, and the project, e.g. pie chart; double click callback in editor, e.g. navigating to URI's, ... | 2 | ||
| logs formatted in N3 | 1 | |||
| Java wrapper for storage with SPARQL 1.1, suitable to be used in the consequent side of a query; | 1 | also wrapper for SPARQL queries that are on the EG project |
||
| Sub-features not in total | TOTAL
18 |
EulerGUI 2.1
| Features
and code changes |
Comments | Estimate
(skilled developper) |
|---|---|---|
| rule base to check Java statements in N3 | check object instanciations;
check method calls: implies to infer type from preceding Java instanciations triples; probably use CWM reification, chained to a mixed N3 rule base; then multi-engine pipeline projects are useful; error display in editor is currently broken; this is an oportunity to fix it, and make it dynamic (not only when user saves the file); but a popup is already helpful NOTE: currently the order of triples is significant alas; switching to rule-based N3 to Drools translation would be beneficial here |
2 |
| local SPARQL storage (TDB ?) | need some thought about what want to do here: persistant store, but
for what ?
|
2 |
| backward chaining engine with user rules and querying SPARQL endpoints | see backward chaining | 6 |
| on-demand loading of features | hopefully reuse Maven pom.xml, plus additional annotations (in N3 leveraging on RDF-plan XML mapping) to achieve something like dynamic OSGi services | 4 |
record user actions in N3, to be able to:
|
task probably related to task extension points in EulerGUI 2.0, because the event recording should be generic for each extension point | 2 |
edit large N3 sources, too big to fit in memory (cf current warning popup when loading a large file) |
use a robust editor, e.g. gvim
NOTE: possibility to do N3 (or SPARQL) queries on this N3 source; deactivated on loading, as it's too big to participate in inference with current engines |
1 |
| TOTAL
17 |
EulerGUI 2.2
| Features
and code changes |
Comments | Estimate
(skilled developper) |
|---|---|---|
| Echo, wicket and/or GWT GUI generation for web applications | see GUI generation for web applications; the first release will just be an example, like the FOAF example remade as a web application | 2 |
| new N3 sources types: machine learning, NLP tools, tags in audio and video files, etc | lots of things to do here ... the job is mainly in choosing tools and use cases | 3 |
| Protégé plugin | leverage on N3 format OWL compatible; time much shorter for a
developer knowing Protégé; also having a plugin for eclipse ontology
plugin NeOn Toolkit would be nice; see also Ontology_editor
in Wikipedia;
a jEdit plugin also makes sense ( note that jEdit has many downloads per day on sf.net : between 1000 and 1500 !!! ); should be quite easy, because EulerGUI already uses jEdit; NOTE: creating several plugins is an oportunity to factor some common semantic pattern of GUI insertion and event transmission |
4 |
| upgrade jEdit | some classes have been copied and modified (bad practice!) from jEdit 4.3.1; jEdit is now at 4.5.0; upgrading can imply asking the jEdit team for some modification; we are probably the only ones to use full jEdit as library ! | 3 |
| completion in N3 editor | use a listener for control - space, or configured key combination for completion; completion wished for N3 prefix and suffix | 4 |
| TOTAL
16 |
You should test EulerGUI snapshots from here on the Maven repository, and take the latest SNAPSHOT :
http://eulergui.sourceforge.net/maven2/eulergui/eulergui/
This is bleeding edge beta stuff (but with all tests have passed)
Read the present User Manual for the EulerGUI IDE for features.
For possible test scenarios, look in manual "Getting started" , or here : explore Semantic Web; for the Java - N3 framework aspect : N3 rules triggering Java actions , configure EulerGUI in N3 .
A likely source of bugs is to look for ontologies with search engines (see Finding ontologies on the Web ), and drag'n'drop them onto EulerGUI.
IMPORTANT
A bug report, to be useful, should include these items:
Then you can report the bug in one of the ways from Support & community.
You can have a look at Monitor source changes to check what are the latest features or bug fixes.
Note: running test on Windows + Cygwin
Tests run for more than 15 minutes and they display windows which may be
disturbing. On Linux this issue is easy to address with Virtual
Desktops. Happily there is an open-source Virtual Desktop solution
on Windows, its' called 'Virtual Dimension'
When it's started, it will put itself in the 'notification area' (it's
located on bottom right corner of the screen in default desktop configuration)
Open the 'hidden icons', locate the one for Virtual Dimension,
then open 'Configure...' with a right click to open the settings, select
the 'Desktop' tab and use [Insert] button to create a new virtual
desktop.
Now open Cygwin Shell from one virtual desktop and start the tests. All
the windows displayed by the tests will only be displayed in this virtual
desktop and you can switch to the other virtual desktop to work on another task
without being disturbed.
Here is the development page.
This is is in the Architecture page.
Thanks to :
Jos De Roo for making Euler and his advices
Luc Peuvrier for his N3 parser
the Drools guys: Edson Tirelli, Mark Proctor
Chimezie Ogbuji for developing FuXi
Roberto Garcia and Steve Battle for their plain XML and XSD converters
Paul for checking the documentation
the eclipse EMF and UML teams
the Jena team
the Pellet team
Thorsten Möller for providing his Maven repository for Pellet
Vincent Aravantinos for solving the problems under Mac
Ruset Zeno for testing and Romanian localization
Olivier Rossel and horus for their coding